

SMS Spam Detector using NLTK
Building an SMS Spam Detector on Python using NLTK Library
Imports and Configuration
import nltk
import pandas as pd
nltk.download_shell()
Reading the File
messages = [line.rstrip() for line in open('smsspamcollection/SMSSpamCollection')]
print(len(messages))
5574
messages[0]
'ham\tGo until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...'
Exploring the messages
for mess_no,message in enumerate(messages[:10]):
print(mess_no,message)
print('\n')
Creating a Dataframe
messages = pd.read_csv('smsspamcollection/SMSSpamCollection',sep='\t',
names=['label','message'])
messages.head()
| label | message | |
|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only ... |
| 1 | ham | Ok lar... Joking wif u oni... |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina... |
| 3 | ham | U dun say so early hor... U c already then say... |
| 4 | ham | Nah I don't think he goes to usf, he lives aro... |
messages.describe()
| label | message | |
|---|---|---|
| count | 5572 | 5572 |
| unique | 2 | 5169 |
| top | ham | Sorry, I'll call later |
| freq | 4825 | 30 |
messages.groupby('label').describe()
| message | ||||
|---|---|---|---|---|
| count | unique | top | freq | |
| label | ||||
| ham | 4825 | 4516 | Sorry, I'll call later | 30 |
| spam | 747 | 653 | Please call our customer service representativ... | 4 |
messages['length'] = messages['message'].apply(len)
messages.head()
| label | message | length | |
|---|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only ... | 111 |
| 1 | ham | Ok lar... Joking wif u oni... | 29 |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina... | 155 |
| 3 | ham | U dun say so early hor... U c already then say... | 49 |
| 4 | ham | Nah I don't think he goes to usf, he lives aro... | 61 |
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
messages['length'].plot.hist(bins=150)
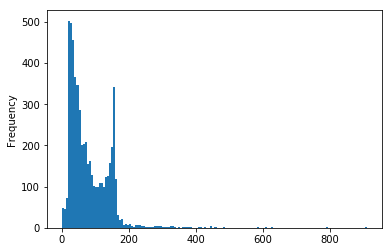
messages['length'].describe()
count 5572.000000
mean 80.489950
std 59.942907
min 2.000000
25% 36.000000
50% 62.000000
75% 122.000000
max 910.000000
Name: length, dtype: float64
Outlier
messages[messages['length']==910]['message'].iloc[0]
"For me the love should start with attraction.i should feel that I need her every time around me.she should be the first thing which comes in my thoughts.I would start the day and end it with her.she should be there every time I dream.love will be then when my every breath has her name.my life should happen around her.my life will be named to her.I would cry for her.will give all my happiness and take all her sorrows.I will be ready to fight with anyone for her.I will be in love when I will be doing the craziest things for her.love will be when I don't have to proove anyone that my girl is the most beautiful lady on the whole planet.I will always be singing praises for her.love will be when I start up making chicken curry and end up makiing sambar.life will be the most beautiful then.will get every morning and thank god for the day because she is with me.I would like to say a lot..will tell later.."
messages.hist(column='length',by='label',bins=60,figsize=(12,4))
array([<matplotlib.axes._subplots.AxesSubplot object at 0x000002A1B9ADBE48>,
<matplotlib.axes._subplots.AxesSubplot object at 0x000002A1B9BC8208>],
dtype=object)

import string
mess = 'Sample message! Notice: it has punctuation'
string.punctuation
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
#remove punctuation from the mess
nopunc = [c for c in mess if c not in string.punctuation]
from nltk.corpus import stopwords
stopwords.words('English')
nopunc = ''.join(nopunc) # remove spaces from punc removed str
nopunc
'Sample message Notice it has punctuation'
nopunc.split()
['Sample', 'message', 'Notice', 'it', 'has', 'punctuation']
clean_mess = [word for word in nopunc.split() if word.lower() not in stopwords.words('English')]
clean_mess
['Sample', 'message', 'Notice', 'punctuation']
#function
def text_process(mess):
"""
1- Remove punctuation
2- Remove stop words
3- Return list of clean words
"""
nopunc = [char for char in mess if char not in string.punctuation]
nopunc = ''.join(nopunc)
return [word for word in nopunc.split() if word.lower() not in stopwords.words('English')]
messages['message'].head(5).apply(text_process)
0 [Go, jurong, point, crazy, Available, bugis, n...
1 [Ok, lar, Joking, wif, u, oni]
2 [Free, entry, 2, wkly, comp, win, FA, Cup, fin...
3 [U, dun, say, early, hor, U, c, already, say]
4 [Nah, dont, think, goes, usf, lives, around, t...
Name: message, dtype: object
from sklearn.feature_extraction.text import CountVectorizer
bow_transformer = CountVectorizer(analyzer=text_process).fit(messages['message'])
print(len(bow_transformer.vocabulary_))
11425
mess4 = messages['message'][3]
print(mess4)
U dun say so early hor... U c already then say...
bow4 = bow_transformer.transform([mess4])
print(bow4)
(0, 4068) 2
(0, 4629) 1
(0, 5261) 1
(0, 6204) 1
(0, 6222) 1
(0, 7186) 1
(0, 9554) 2
bow_transformer.get_feature_names()[9554]
'say'
messages_bow = bow_transformer.transform(messages['message'])
print('Shape of Sparse Matrix: ',messages_bow.shape)
Shape of Sparse Matrix: (5572, 11425)
messages_bow.nnz
50548
from sklearn.feature_extraction.text import TfidfTransformer
tfidf_transformer = TfidfTransformer().fit(messages_bow)
tfidf4 = tfidf_transformer.transform(bow4)
print(tfidf4)
(0, 9554) 0.5385626262927564
(0, 7186) 0.4389365653379857
(0, 6222) 0.3187216892949149
(0, 6204) 0.29953799723697416
(0, 5261) 0.29729957405868723
(0, 4629) 0.26619801906087187
(0, 4068) 0.40832589933384067
tfidf_transformer.idf_[bow_transformer.vocabulary_['university']]
8.527076498901426
messages_tfidf = tfidf_transformer.transform(messages_bow)
from sklearn.naive_bayes import MultinomialNB
spam_detect_model = MultinomialNB().fit(messages_tfidf,messages['label'])
spam_detect_model.predict(tfidf4)[0]
'ham'
messages['label'][3]
'ham'
all_pred = spam_detect_model.predict(messages_tfidf)
from sklearn.model_selection import train_test_split
msg_train, msg_test, label_train, label_test = train_test_split(messages['message'],messages['label'],test_size=0.3)
Building up a Pipeline for Classification
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('bow',CountVectorizer(analyzer=text_process)),
('tfidf',TfidfTransformer()),
('classifier',MultinomialNB())
])
pipeline.fit(msg_train,label_train)
Pipeline(memory=None,
steps=[('bow', CountVectorizer(analyzer=<function text_process at 0x000002A1B9DE3950>,
binary=False, decode_error='strict', dtype=<class 'numpy.int64'>,
encoding='utf-8', input='content', lowercase=True, max_df=1.0,
max_features=None, min_df=1, ngram_range=(1, 1), preprocesso...f=False, use_idf=True)), ('classifier', MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True))])
Predictions and Evaluation
predictions = pipeline.predict(msg_test)
from sklearn.metrics import classification_report
print(classification_report(label_test,predictions))
precision recall f1-score support
ham 0.96 1.00 0.98 1462
spam 1.00 0.70 0.82 210
micro avg 0.96 0.96 0.96 1672
macro avg 0.98 0.85 0.90 1672
weighted avg 0.96 0.96 0.96 1672